How the cloud has changed detection
That the cloud has been a game-changer for many organizations is reflected in the annual revenues of major cloud service providers (measured in the tens of billions).
As one might expect, attacks against cloud environments have become more common too. Public disclosure of data breaches from organizations' cloud environments, and the experience of our Incident Response (IR) teams, highlights this. The security industry has been comparatively slow to adapt to that reality from a detection standpoint.
The concept of cloud-native or cloud-first environments and architectures, and the DevOps culture that drives them, has led to a number of changes in the attack surface of an organization. The traditional concept of a perimeter means little for those with a mature cloud posture, where critical assets often sit outside the on-premise estate. Cloud services are, by default, exposed to the internet at large. Access control becomes a question of identity-based access management rather than network segregation, as is the case on-premise. In addition, it's common to see extensive use of third-party services: Github for managing source code, Travis or CircleCI for continuous integration and deployment (CI/CD), Slack for communications, and Office365 or G Suite for documents. This results in a loss of traditional defence in depth – organizations have to pay closer attention to what is deployed in the cloud, and how, as it can take fewer misconfigurations to unintentionally expose a service, or create additional risk.
The cloud does of course bring many benefits. Depending on the services you use, cloud providers themselves take care of many of the typical security concerns of a system, allowing a security team to focus their time on configuring systems to meet their needs. The automation possible with most of the major providers, given the extensive API support, also makes it easier to identify and remediate security issues than has historically been possible. When combined, this allows a smaller security team to manage far larger estates than would have historically been possible.
The challenges of attack detection have changed
On premise, the primary problems associated with attack detection are reasonably well understood. Excluding the perennial arms race between attackers and defenders, a handful of key problem areas stand out.
Asset Management
The first problem with defending large enterprise networks is asset management. How can you defend everything if you're not sure you know about everything that needs defending? This is a large and complex problem, and a significant market exists for vendor products that attempt to solve the problem of asset discovery.
Log Storage
Gathering telemetry from across a large organization is often complicated by log storage issues on premise. With major security information and event information (SIEM) solutions, visibility often comes with a licensing cost for the extra data processed. Storage also requires planning and provisions from relevant teams in advance.
The logistics of deploying security tooling
In a large enterprise, it is not easy to ensure that endpoint agents, network taps, or other detective tooling are deployed comprehensively and consistently across the entire estate. This is particularly complicated when operations and teams are geographically distributed with complex network topologies.
The variety (and age) of operating systems and technologies in use
A multitude of systems commonly comprise large enterprise networks , with varying age and provenance. Legacy systems are commonly used, despite their incompatibility with tooling. They may also lack the audit functionality for generating adequate telemetry, i.e. the ability to log, with enough granularity, significant security events that would be used as a data source for identifying future malicious activity.
On-premise attack detection is not a new problem space though. There is a wide understanding of it within the industry, good knowledge bases such as MITRE ATT&CK, and plentiful vendor products available to support an organization attempting to achieve its detection strategy.
Challenges from a cloud perspective
The challenges of detection on-premise are paralleled, though of course different, in the cloud. For one, asset management is, much simpler in theory; querying the APIs offered by cloud providers should generate a list of deployed resources in an organization's cloud accounts. The issue in this instance becomes shadow IT – when anyone can open a cloud account with just a credit card, how are you meant to validate legitimate users?
Log storage becomes less of an issue with regards to up-front capacity planning and management, as cloud providers will offer essentially unlimited storage, if you have the means to pay for it.
Tooling deployment becomes much simpler in many respects. Golden images allow security teams to ensure that all virtual machines are running the approved security tools configured in the right way, and many managed services simply don't require the endpoint agent installation, log forwarding or similar tooling that infrastructure-as-a-service does.
Lastly, while most cloud estates run up-to-date operating systems and software, the cloud presents its own technology challenges, and requires a skill set not historically present in many security teams. In addition, security product vendors have been comparatively slow to move into this space, although this is now picking up. Frameworks like MITRE ATT&CK have expanded their coverage over the last few months to include some of the most common tools, tactics, and procedures (TTPs) used in attacks against the cloud.
Attackers' objectives have not changed, but their TTPs have
Fundamentally, an attacker's goals have not changed as a result of target organizations moving to the cloud. They will typically still attempt to compromise an environment to fulfil one of three primary goals:
- Make money
- Steal corporate secrets
- Cause reputational damage
Through experience, we’ve seen that most cloud environments are currently compromised via one of three cloud native routes, excluding phishing attacks. These are:
- Open storage buckets, especially in AWS with S3
- Application vulnerabilities or misconfigurations allowing an attacker to pivot into the cloud via the compute metadata service
- API or Access Keys, or other forms of credentials, being accidentally exposed. This is frequently via public source code repositories
Providers offer mitigations for a number of these issues. For instance, AWS notifies users of publicly exposed S3 buckets and credentials identified in the public realm. It has also released the Instance Metadata Service (IMDS) v2 to help mitigate against application-level vulnerabilities accessing the EC2 metadata service. However, these measures are mostly reactive, as in the case of IMDSv2, which can’t be made the default option as it is not backwards compatible. As such, it's likely that the vulnerabilities above will continue in popularity for some time yet.
Attackers have also automated the identification and exploitation of these vulnerabilities to varying degrees. Exposed API keys, for example are commonly leveraged for the purposes of cryptocurrency mining. The median time to compromise of AWS access keys posted to GitHub is 20 seconds, thanks to the automation used by attackers.
Alongside the changing nature of TTPs, a fundamental mindset shift is required for attack detection in the cloud: away from known malicious behaviour, and towards identifying abuse of legitimate functionality. On premise there is a spectrum of malicious behaviour, from malicious activity that can be clearly identified (such as Mimikatz) to abuse of legitimate functionality that may or may not appear to be malicious (such as unusual Kerberos activity from a user).

In the cloud, this breaks down. A lot of malicious activity will not appear as such, with attackers leveraging capabilities exposed by the cloud providers’ APIs to achieve their objectives.
The control plane
On-premise, the highest fidelity telemetry typically comes from network endpoints. A combination of Endpoint Detection and Response products, system logs and anti-virus systems generate a range of telemetry that is fed into a SIEM. There will also be provision of automated responses to known bad activity. This is a fairly well-understood space, and exactly what to hunt for in endpoint-based telemetry sources has long been well-defined by frameworks such as MITRE ATT&CK.
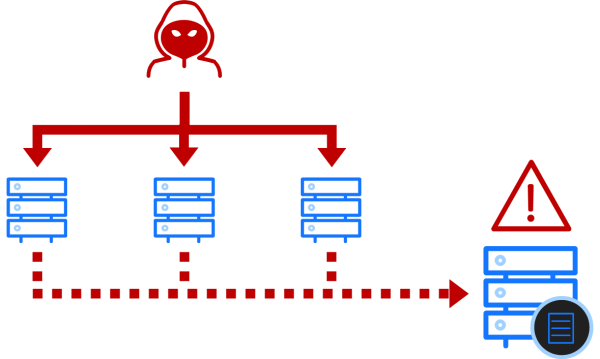
Fig. 1. The on-premise control plane where attackers gain access via network endpoints
The core detection space within the cloud has switched away from endpoint-based telemetry, towards telemetry of actions taken against the control plane. In the context of the cloud, the control plane is the APIs that allow an administrator to create, modify, and destroy resources within a cloud environment. This includes both the APIs exposed by the providers themselves, such as those leveraged by the AWS and Azure web consoles and CLIs, and any APIs exposed by software such as Kubernetes or Cloud Foundry.
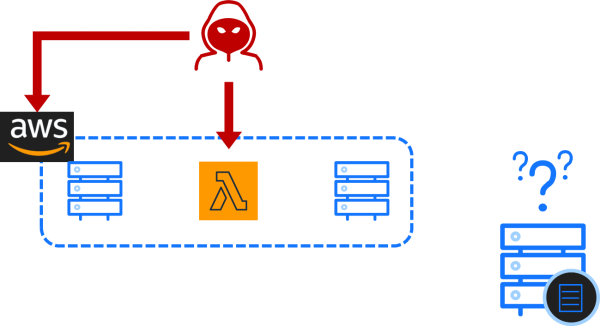
Fig. 2. The cloud control plane formed of cloud provider and service APIs
Attackers will use these APIs to perform actions that move them closer to their goals. For instance, they may add new user accounts, modify the permissions of an existing account, or grant access to resources from external locations. They'll also likely use such native capabilities to perform actions on objectives by accessing sensitive data or creating additional compute resources for the purpose of bitcoin mining.
Understanding the context to understand these actions within the environment aids successful detection in the cloud. Teams working successfully to detect malicious activity are able to identify what comprises normal behavior in the account, and what may be malicious. This will, in time, likely drive closer integration between the development and infrastructure teams, and the security function which defends their environments.
The use of continuous integration and deployment pipelines provides a good example of the contexualization requirement. Should a change be made by the pipeline entity, then it's likely that the change was intended. Should a change be made by an entity outside of the pipeline when that is atypical for the environment, then it's likely to be anomalous and worthy of further investigation.
Architecting for detection
In addition to ensuring that the right log sources are configured and ingested, it is important to consider the architecture of both the cloud estate and the detection platform. Where a centralized Security Incident and Event Management (SIEM) system is already in use within an organization, WithSecure recommends that they forward their cloud telemetry into these existing platforms. This allows security staff to leverage existing knowledge and tooling investment to support new cloud environments. It will also simplify the identification of hybrid killchains, where attackers pivot on-premise from the cloud or vice versa.
The telemetry sources discussed above, configured in all cloud environments owned by an organization, should all feed into a central cloud account. This provides a central source of truth for cloud log data and log configuration, which is particularly important in larger organizations making broad use of a given cloud provider. Where multiple cloud providers are in use, it often makes sense to deploy a single such account per cloud provider to take advantage of native integrations, and forward from each central account to an organisation-wide, cloud-agnostic SIEM.
Most cloud providers advocate the use of separate accounts, projects, or similar for security focused activity such as logging and monitoring, and WithSecure agrees with this approach. This is illustrated within guidance such as the AWS Well Architected framework.
Separating all security-focused services into their own account or similar allows a hard permissions boundary to be enforced on the services hosting security functions, with write-only permissions to log destinations granted to project accounts and resources. In addition, access to the account should be restricted to security and administrative personnel who have a requirement to access the account. This ensures that an attacker who compromises a project's cloud account or project cannot also alter or delete log data that would provide forensic indicators of their activity. It also reduces the potential blast radius of other changes made elsewhere within a cloud estate, helping to ensure that the security functions remain unaffected by the constantly evolving nature of other projects.
It's worth considering whether to segregate this further than purely an isolated account within the existing organization or enterprise enrolment, to a separate cloud entity entirely. This has the largest impact in situations where access to cloud environments is provisioned via on-premise identity providers and authorization systems, such as via Active Directory (AD). Should this step be taken, a separate centralized authentication system should be put in place, be it with native cloud users or a separate single sign-on (SSO) platform. This step would ensure that an attacker pivoting into regular project cloud accounts or projects, following an on-premise compromise, could not also compromise the telemetry and security functionality.
Detecting attacks against cloud environments
With every breach headline comes reputational damage for the organization involved. In the case of cloud breaches, the headline often includes not just the breached organization, but also the cloud provider they were hosting their systems on. As a result, there has been a strong incentive for the providers to develop capabilities in this space, and they've risen to the challenge. The services offered fall broadly into two groups: detection-focused services, and services that provide telemetry that is relevant to detection and response.
Detection services
Cloud providers have been working towards providing integrated SIEMs and attack detection systems, such that those without the resources to manage and maintain their own detective capability can leverage the providers' offerings instead. The most prominent of these currently are:
- AWS GuardDuty, which functions as an IDS for AWS accounts and resources
- Azure Sentinel, which is a cloud-native SIEM capable of ingesting telemetry from Azure and other cloud platforms
These services should not be seen as a silver bullet, but they provide a valuable detective capability, and often have access to data sources that are not directly exposed to end users. For example, GuardDuty ingests DNS activity logs from Amazon's Route53 DNS service, which are not made available separately. These tools are particularly useful for organizations without significant dedicated security resource, as they'll provide detection of many of the low-sophistication attacks without requiring significant investment.
Telemetry services
In addition to providing detection-focused services as outlined above, all three major cloud providers offer a number of different services that will provide some sort of telemetry. These fall into several main categories:
- Control plane activity logs
- Network traffic logs
- Configuration change logs
Control plane activity logs
Services falling into these categories provide audit logs of who performed what activity at a control plane level within a cloud environment. This includes events such as the creation and deletion of users, compute resources, databases, and so on, along with the deployment and modification of policies, permissions and security related services. It also typically contains authentication data, indicating where users are connecting from, what access or API keys were used, whether the user logged in with multi-factor authentication, and so on.
From a defensive perspective, these logs are typically the most critical within a cloud environment. Key indicators of credentials being misused will be found here, as will indicators of enumeration activity, attempts to escalate privileges, or deploy new resources. Use cases based on these logs should typically be focused on:
- Creation, modification or deletion of users, policies, roles and other components of the IAM/RBAC model within an environment
- Alteration or deletion of log sources and other security critical services
- Repeated failed authentication attempts
- Attempts to use credentials from unusual locations or in unusual time zones
- Failed attempts at API calls commonly used for enumeration, such as listing users, groups, roles, policies and so on.
Network traffic logs
Netflow and similar traffic metadata formats can be used to identify malicious traffic in an on-premise estate. These log sources provide the same functionality in the cloud. They are typically most useful in environments predominantly formed of virtual machines and other IaaS components, but some Platform as a Service (PaaS) resources can be deployed into a subnet or VPC to provide the same level of network visibility. In addition, most services are isolated at the network level by default in the cloud. This reduces the opportunity for an attacker to move laterally between systems in the traditional sense. While typically less useful than control plane activity logs, network traffic logs provide visibility into communications between systems within the cloud and to external systems. This can be useful to identify compromised hosts beaconing out to known malicious IP addresses or domains, or to flag anomalous traffic moving between systems within the network or in unusual volumes. From a detection standpoint, it is generally possible to reuse existing network-based use cases from on-premise to some degree.
Configuration change logs
AWS and Azure both offer services that react to changes made within an environment. Depending on how they're configured, they can either raise notifications of changes made, or perform an automated configuration review based on rulesets defined by the user. This can serve both as a complimentary data source to Control Plane Activity Logs, but also to identify and auto-remediate specific high-impact attacker activity. For instance, rules could be implemented to enforce correct configuration of other telemetry sources, and for alerts to be raised should any of these configurations change.
Services by cloud provider
Service type | AWS | Azure | Google Cloud |
|---|---|---|---|
Control plane activity logs | |||
| Network traffic logs | |||
| Configuration change logs |
Other telemetry sources
In addition to the above, other cloud-native services, such as managed storage platforms, serverless computation, and secrets management services offer their own log sources. These provide service-specific insight into the requests submitted and processing that takes place within. These log sources can provide valuable telemetry under certain circumstances depending on architectural decisions, log volumes and a number of other considerations. These log sources should be considered on a case-by-case basis, depending on the value they will provide for each instance of a service within a given environment, to ensure that only telemetry likely to be useful to analysts is ingested.
Conclusion
Some aspects of detection have changed in the cloud, not least of which the nature of the data and the visibility available to defenders. That said, many things have stayed the same - – attacker motivations in particular - – and that allows defenders to translate many of the existing use cases into the cloud. In addition to doing this in new cloud environments, effective defenders consider how to best defend against the three most common exploitation vectors seen in the cloud at present:
- Publicly-exposed resources
- Metadata service exploitation
- Credential theft or accidental publication
Furthermore, organizations should consider detection and response in their cloud architectures as early in their cloud journey as possible. They should also ensure that a centralized process exists to feed these telemetry sources into a centralized SIEM in order to be made available to analysts. Making this telemetry ingestion as smooth as possible for new cloud environments, accounts, and subscriptions will be a critical factor in ensuring visibility across an organization's estate, especially as cloud adoption scales.